


The GEB Index methodology revolutionizes entrepreneurial assessment by using a 3-layer indirect framework to measure how founders actually behave, rather than how they describe themselves.
Why Asking Founders “Who They Are” Almost Never Works
In the high-stakes world of startup creation, the difference between a founder who survives a liquidity crisis and one who freezes under pressure is rarely captured by a self-report questionnaire. When asked directly, most founders will describe themselves as resilient, adaptable, and ethically grounded — regardless of how they actually behave when the runway shrinks to six weeks and the lead engineer threatens to quit.
This is not a character flaw. It is a well-documented measurement problem. Traditional personality inventories and self-assessment scales suffer from two intersecting vulnerabilities:
- Intentional response distortion (faking): In high-stakes contexts — applying for funding, seeking accelerator admission, recruiting co-founders — founders have every incentive to present an idealized version of themselves. Research in organisational psychology has repeatedly shown that social desirability bias inflates self-ratings on positive traits by as much as one full standard deviation.
- Unintentional self-ignorance: Even with perfect honesty, individuals are often poor judges of their own behavioural patterns. The cognitive biases that impair entrepreneurial decision-making (overconfidence, confirmation bias, the Dunning-Kruger effect) also impair self-awareness. A founder who habitually micromanages may genuinely believe they are “thoroughly engaged.”
The General Entrepreneurial Behavior (GEB) Index was designed to circumvent both problems simultaneously. It does not ask founders who they think they are. It observes how they choose to act under conditions of realistic entrepreneurial pressure — and infers behavioural patterns indirectly, through a three-layer methodology that transforms comparative judgment into normative, actionable data.
Layer 1: Forced-Choice Situational Judgment in the GEB Index Methodology

The GEB contains 75 situational judgment scenarios (SJTs), each describing a realistic entrepreneurial crisis. These are not hypotheticals about “what would you do if you were a good leader.” They are concrete, ambiguous, and pressure-sensitive situations drawn from the analysis of over 10,000 startup post-mortems and verified by the Supsindex Faculty network.
In each scenario, the founder is presented with between three and four plausible responses and must select two: the most effective action and the least effective action.
Why forced choice defeats faking
In a standard Likert scale (“Rate your resilience from 1 to 5”), the socially desirable answer is obvious. Every founder knows they should rate themselves highly. There is no penalty for endorsing every positive trait.
In a forced-choice SJT, however, the founder must make tradeoffs. Consider a simplified example from the GEB bank:
Scenario: Your startup has three months of runway remaining. A major customer offers a contract that would extend runway by six months, but requires you to deprioritise a feature that your engineering team has already spent 200 hours building. Your co-founder argues strongly against the pivot.
Options:
A. Accept the contract immediately to secure runway, overriding your co-founder.
B. Reject the contract and continue on the original roadmap to maintain team morale.
C. Call a one-hour meeting to review data on both options, then make a final decision.
D. Defer the decision to your board of advisors.
The founder must rank these by effectiveness. Option A may signal decisive leadership — but also autocratic tendencies. Option B signals loyalty to the team — but also rigidity and financial recklessness. Option C signals deliberative process — but may be too slow. Option D signals humility — but also abdication.
Because all options are plausible (none is absurd), the founder cannot simply “pick the virtuous answer.” They must reveal their default tradeoff preferences: speed vs. consensus, analysis vs. intuition, authority vs. delegation.
Empirical advantage
Meta-analyses of personnel selection research have consistently found that SJTs outperform self-report personality measures in predicting job performance, with validity coefficients approximately 30–50% higher. The advantage is largest precisely in high-stakes contexts where impression management is most likely. Forced-choice SJTs also reduce adverse impact across demographic groups, because the comparative format reduces cultural response style effects (e.g., the tendency in some cultures to endorse extreme responses).
Layer 2: Thurstonian Item Response Theory — From Comparative Choices to Normative Scores
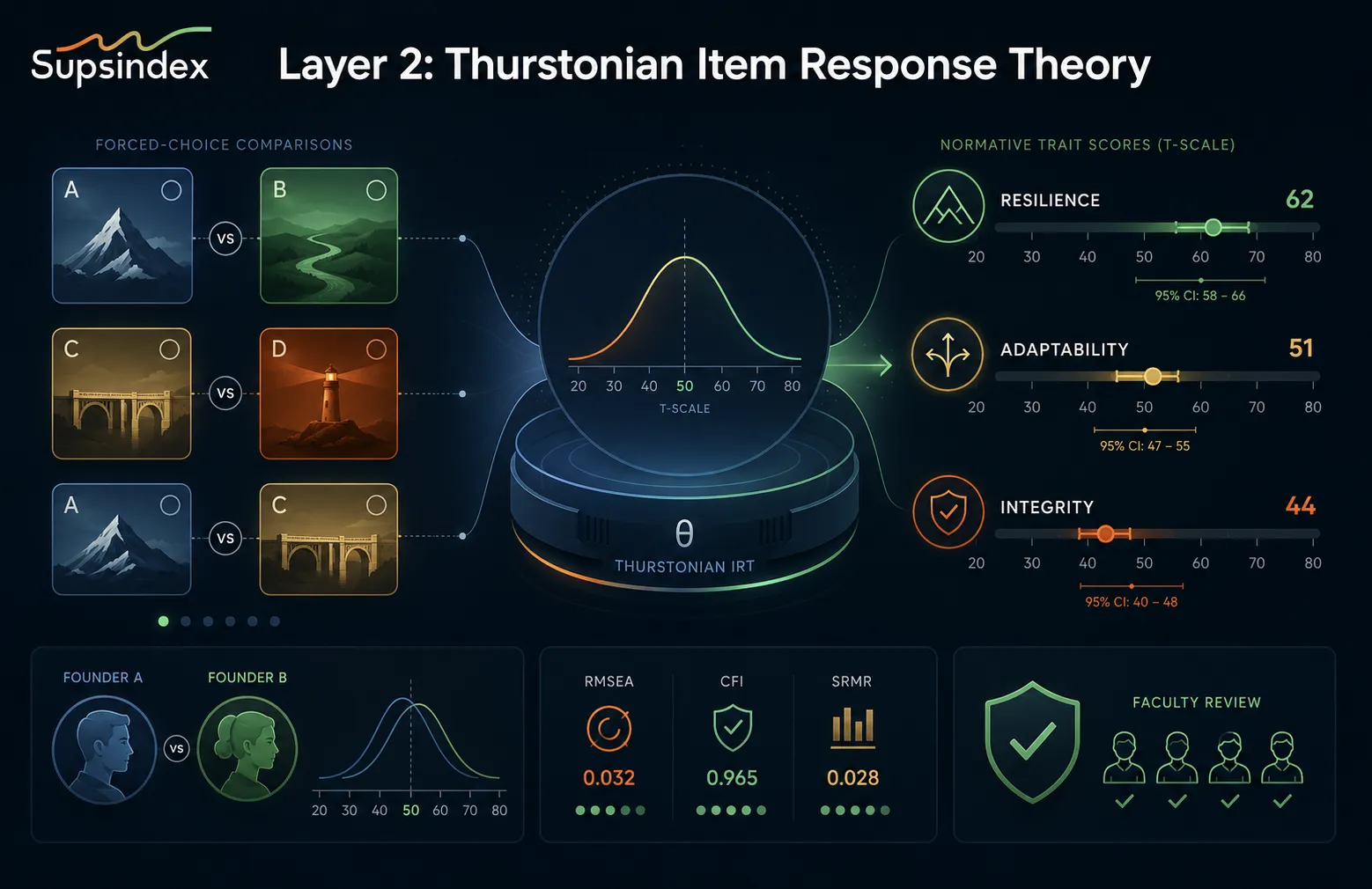
The forced-choice format solves the faking problem but introduces a new one: ipsative data. Ipsativity means that scores are mathematically constrained within each person. If a founder ranks Option A as “most effective” and Option C as “least effective,” the implied utilities for B and D are suppressed. Across the whole test, a founder cannot score high on all positive traits simultaneously — even if they genuinely possess them.
This is the central statistical challenge of forced-choice measurement. Traditional scoring simply sums ranks or assigns points to “correct” choices, producing scores that are not comparable across individuals. You cannot meaningfully say Founder A is more resilient than Founder B, because each founder’s scores are locked inside their own internal tradeoffs.
The Thurstonian solution
Supsindex solves this problem by implementing a Thurstonian Item Response Theory (T-IRT) model, originally developed by the psychometrician Louis Leon Thurstone and later extended to forced-choice formats by Brown and Maydeu-Olivares (2011, 2013).
The core insight is straightforward but mathematically powerful: every choice between options reveals a comparison of latent utilities. If a founder selects Option A as “most effective” over Option B, the model infers that the founder’s latent utility for A exceeds that for B, within measurement error.
By aggregating hundreds of such comparisons across 75 scenarios, the T-IRT model estimates absolute (normative) trait scores on a continuous scale — typically transformed to a T-scale with mean = 50 and SD = 10.
What this enables
- Between-person comparability: We can now say, with statistical confidence, “Founder A’s resilience score is 62, placing her one standard deviation above the mean; Founder B’s score is 48, placing him 0.2 standard deviations below the mean.” This is the foundation of quartile rankings, investor benchmarking, and cohort analysis.
- No forced tradeoffs: A founder can legitimately score high on both adaptability and integrity. The Thurstonian model does not artificially suppress one trait because another was prioritised in a specific scenario.
- Precision that varies by construct: Unlike Classical Test Theory, which assumes uniform measurement error, T-IRT reports marginal reliability coefficients that vary by trait level. The GEB dashboard shows confidence intervals, not just point estimates, so founders and investors see exactly where measurement is most and least precise.
Model fit and quality control
Supsindex routinely monitors absolute and relative fit indices — including RMSEA (root mean square error of approximation), CFI (comparative fit index), and SRMR (standardised root mean square residual) — to confirm that the T-IRT model adequately represents the data. Items that show poor fit or differential functioning across demographic groups are flagged by the Faculty network, quarantined, and revised or retired. The target rejection rate — new questions rejected by Faculty — is held below 10%, ensuring continuous quality improvement.
Layer 3: Dual-Engine Reporting — Strength Patterns and Risk Signatures

A single behavioural score, no matter how precisely estimated, tells only half the story. The GEB report is structured as a dual-engine analysis, simultaneously modelling two complementary dimensions:
The Strength Engine — Positive behavioural constructs
The GEB measures 15 positive behavioural constructs demonstrated in entrepreneurial success research to predict venture survival. These include:
- Resilience (recovery from setbacks)
- Calculated risk-taking (distinct from recklessness)
- Adaptability under uncertainty
- Ethical integrity (resistance to corner-cutting)
- Communication and collaboration (team-oriented decision-making)
- Metacognitive awareness (monitoring one’s own decision processes)
Each construct is estimated from multiple SJTs, triangulated across different contexts (team conflict, customer rejection, investor negotiation, resource scarcity). The report displays the founder’s percentile rank on each construct, benchmarked against founders in the same industry, stage, and ecosystem.
The Risk Engine — Cognitive bias susceptibility
The same behavioural data that reveal strengths also expose vulnerabilities. The GEB’s Risk Engine measures susceptibility to 20 cognitive and behavioural derailers that systematically undermine entrepreneurial decision-making, including:
- Overconfidence bias (overestimating the probability of positive outcomes)
- Confirmation bias (seeking evidence that supports pre-existing beliefs)
- Micromanagement tendency (inability to delegate reversible decisions)
- Sunk cost fallacy (escalating commitment to failing strategies)
- Groupthink susceptibility (suppressing dissent for social harmony)
Critically, the GEB does not simply ask founders whether they suffer from these biases. It infers bias susceptibility from choice patterns across scenarios. A founder who consistently selects options that reject disconfirming evidence, even when that evidence is presented objectively, will receive an elevated “confirmation bias” risk score regardless of their self-perception.
The socially desirable distractor — A built-in bullshit detector
Each SJT includes at least one option that is intentionally engineered to be socially desirable but behaviourally ineffective. For example, an option framed as “supportive checking-in” may, in context, actually encode micromanagement. An option framed as “decisive leadership” may encode reckless unilateral action.
Novice founders — or those with high impression-management motivation — select these options because they sound virtuous. Experienced founders — or those with higher metacognitive awareness — reject them because they recognise the hidden cost.
The GEB tracks the frequency of socially desirable distractor selection and reports it as a safety score: the higher the score, the lower the founder’s susceptibility to “looking good” at the expense of “being effective.” This is a direct behavioural measure of intellectual humility and epistemic vigilance.
What the GEB Does Not Measure — And Why That Matters
No assessment should claim to measure everything. The GEB is deliberately not a diagnostic clinical instrument. It does not diagnose mental health conditions, nor should it be used as a substitute for professional psychological evaluation. It is a behavioural measurement tool for entrepreneurial contexts, validated against startup outcomes, not clinical populations.
The GEB also does not measure technical knowledge (that is the domain of the FPA), nor does it measure local ecosystem awareness (the EEA). The three indices are designed to be complementary: FPA for cognitive readiness, GEB for behavioural patterns, EEA for contextual fit. Triangulation across all three produces the highest predictive validity.
From Layers to Action — The Purpose of Indirect Measurement
The three-layer methodology is not academic complexity for its own sake. Each layer serves a concrete operational purpose:
| Layer | Purpose | Output |
|---|---|---|
| Forced-choice SJTs | Reduce faking and social desirability bias | Rank-ordered choices across 75 scenarios |
| Thurstonian IRT | Convert ipsative comparisons to normative, comparable scores | Absolute trait estimates (T-scale, percentiles, confidence intervals) |
| Dual-engine reporting | Separate strengths from risks; detect socially desirable responding | Behavioural radar charts, risk signatures, safety score |
The final GEB report does not merely label the founder (“you are resilient”). It provides:
- A behavioural radar chart showing percentile ranks on 15 constructs
- A risk signature flagging susceptibility to specific cognitive biases
- A safety score quantifying resistance to impression management
- Confidence intervals for each estimate, reflecting measurement precision
- Systemic forcing functions — operational rules designed to guardrail the founder’s natural blind spots (e.g., “implement a 24-hour cooling-off rule before strategic pivots” because the founder’s bias pattern indicates overconfidence under time pressure)
Why This GEB Index Methodology Matters for the Entrepreneurial Ecosystem
The startup ecosystem loses hundreds of billions of dollars annually to preventable founder error. Much of this error stems not from lack of knowledge, but from behavioural patterns that founders cannot see in themselves — and that traditional assessment methods cannot detect.
The GEB’s indirect methodology is not a personality test dressed in new clothing. It is a behavioural measurement instrument built on a different epistemological foundation: we cannot trust what people say about themselves in high-stakes contexts, so we observe what they choose when the tradeoffs are real and the right answer is neither obvious nor safe.
By combining forced-choice SJTs, Thurstonian IRT, and dual-engine reporting, the GEB produces behavioural profiles that are resistant to faking, comparable across individuals, and actionable for founders, mentors, and investors. It does not tell founders who they are. It tells them how they are likely to behave when the pressure is on — and gives them a roadmap, not to change their personality, but to redesign their environment around their predictable blind spots.
That is the difference between assessment and diagnosis. That is the purpose of indirect measurement. And that is what makes the GEB a scientific instrument, not a quiz.
References
- Brown, A., & Maydeu-Olivares, A. (2011). Item response modeling of forced-choice questionnaires. Educational and Psychological Measurement, 71(3), 460–502.
- Brown, A., & Maydeu-Olivares, A. (2013). How IRT can solve problems of ipsative data in forced-choice questionnaires. Psychological Methods, 18(1), 36–52.
- Dweck, C. S. (2006). Mindset: The new psychology of success. Random House.
- Kahneman, D. (2011). Thinking, fast and slow. Farrar, Straus and Giroux.
- Salgado, J. F., & Tauriz, G. (2014). The five-factor model, forced-choice personality inventories and performance: A meta-analysis. International Journal of Selection and Assessment, 22(1), 37–48.
- Supsindex Scientific Team. (2025). GEB Scientific Model: Assessing the Entrepreneurial Mindset. Supsindex Knowledge Base.
